Module 1
Ansible
Découvrir le couteau suisse de l’automatisation et de l’infrastructure as code.
Supports de formation : Elie Gavoty, Alexandre Aubin et Hadrien Pélissier
Sous licence CC-BY-NC-SA - Formations Uptime
Découvrir le couteau suisse de l’automatisation et de l’infrastructure as code.
Ansible est un gestionnaire de configuration et un outil de déploiement et d’orchestration très populaire et central dans le monde de l'infrastructure as code (IaC).
Il fait donc également partie de façon centrale du mouvement DevOps car il s’apparente à un véritable couteau suisse de l’automatisation des infrastructures.
Ansible a été créé en 2012 (plus récent que ses concurrents Puppet et Chef) autour d’une recherche de simplicité et du principe de configuration agentless.
Très orienté linux/opensource et versatile il obtient rapidement un franc succès et s’avère être un couteau suisse très adapté à l’automatisation DevOps et Cloud dans des environnements hétérogènes.
Red Hat rachète Ansible en 2015 et développe un certain nombre de produits autour (Ansible Tower, Ansible container avec Openshift).
Ansible est agentless c’est à dire qu’il ne nécessite aucun service/daemon spécifique sur les machines à configurer.
La simplicité d’Ansible provient également du fait qu’il s’appuie sur des technologies linux omniprésentes et devenues universelles.
De fait Ansible fonctionne efficacement sur toutes les distributions linux, debian, centos, ubuntu en particulier (et maintenant également sur Windows).
Ansible est semi-déclaratif c’est à dire qu’il s’exécute séquentiellement mais idéalement de façon idempotente.
Il permet d’avoir un état descriptif de la configuration:
Peut être utilisé pour des opérations ponctuelles comme le déploiement:
Les cas d’usages d’Ansible vont de …:
petit:
moyen:
grand:
Ansible est très complémentaire à docker:
docker_container.Maintenant un peu abandonné, Ansible Container rend possible de construire et déployer des conteneurs docker avec du code ansible. Concrètement le langage Ansible remplace le langage Dockerfile pour la construction des images Docker.
Pour l’installation plusieurs options sont possibles:
sudo apt-add-repository --yes --update ppa:ansible/ansiblepip le gestionnaire de paquet du langage python: sudo pip3 install
sudo pip3 install ansible --upgradePour voir l’ensemble des fichiers installés par un paquet pip3 :
pip3 show -f ansible | less
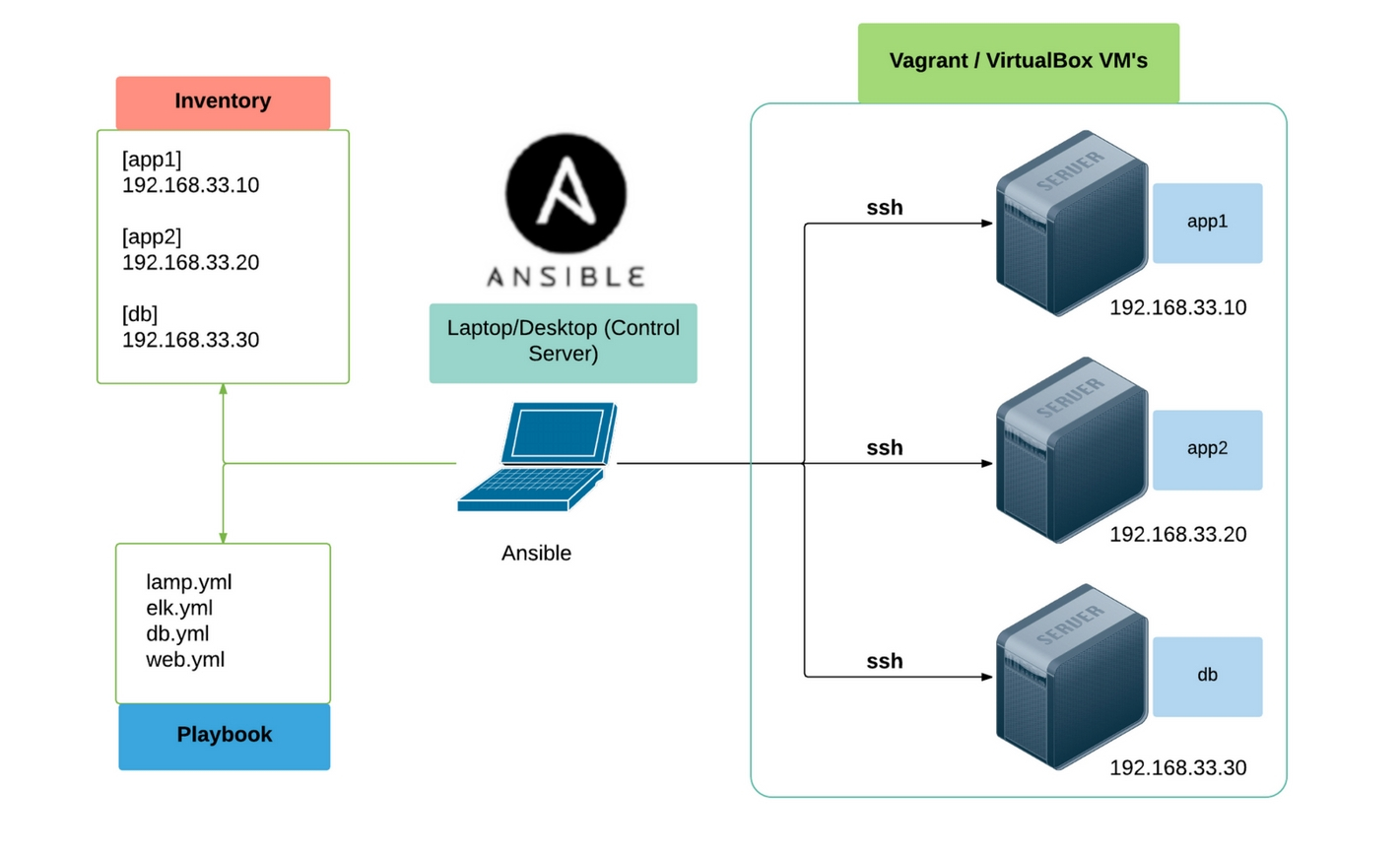
Pour tester la connexion aux serveurs on utilise la commande ad hoc suivante. ansible all -m ping
Il s’agit d’une liste de machines sur lesquelles vont s’exécuter les modules Ansible. Les machines de cette liste sont:
exemple:
[all:vars]
ansible_ssh_user=elie
ansible_python_interpreter=/usr/bin/python3
[worker_nodes]
workernode1 ansible_host=10.164.210.101 pays=France
[dbservers]
pgnode1 ansible_host=10.164.210.111 pays=France
pgnode2 ansible_host=10.164.210.112 pays=Allemagne
[appservers]
appnode1 ansible_host=10.164.210.121
appnode2 ansible_host=10.164.210.122 pays=Allemagne
Les inventaires peuvent également être au format YAML (plus lisible mais pas toujours intuitif) ou JSON (pour les machines).
On a souvent besoin dans l’inventaire de précisier plusieurs options pour se connecter. Voici les principales :
ansible_host : essentiel, pour dire à Ansible comment accéder à l’hostansible_user : quel est l’user à utiliser par Ansible pour la connexion SSHansible_ssh_private_key_file : où se trouve la clé privée pour la connexion SSHansible_connection : demander à Ansible d’utiliser autre chose que du SSH pour la connexionansible_python_interpreter=/usr/bin/python3 : option parfois nécessaire pour spécifier à Ansible où trouver Python sur la machine installéeAnsible se configure classiquement au niveau global dans le dossier /etc/ansible/ dans lequel on retrouve en autre l’inventaire par défaut et des paramètre de configuration.
Ansible est très fortement configurable pour s’adapter à des environnement contraints. Liste des paramètre de configuration:
Alternativement on peut configurer ansible par projet avec un fichier ansible.cfg présent à la racine. Toute commande ansible lancée à la racine du projet récupère automatiquement cette configuration.
pip en lançant:pip install ansible
ansible --version
=> 2.9.x
ansible all -m ping. Que signifie-t-elle ?-vvv pour mettre en mode très verbeux. Ce mode est très efficace pour débugger lorsqu’une erreur inconnue se présente. Que se passe-t-il avec l’inventaire ?ansible en vous connectant à votre machine localhost et en utilisant le module ping.hotelocal ansible_host=127.0.0.1 ansible_connection=local dans l’inventaire par défaut (le chemin est indiqué dans). Et pinguer hotelocal.python3 -m pip install --user argcomplete
activate-global-python-argcomplete --user
LXD est une technologie de conteneurs actuellement promue par Canonical (ubuntu) qui permet de faire des conteneur linux orientés systèmes plutôt qu’application. Par exemple systemd est disponible à l’intérieur des conteneurs contrairement aux conteneurs Docker.
Incus est le successeur de LXD, abandonné par ses devs à cause des choix de Canonical.
Affichez la liste des conteneurs avec incus list. Aucun conteneur ne tourne.
Maintenant lançons notre premier conteneur centos avec incus launch images:centos/7/amd64 centos1.
Listez à nouveau les conteneurs lxc.
Ce conteneur est un centos minimal et n’a donc pas de serveur SSH pour se connecter. Pour lancez des commandes dans le conteneur on utilise une commande LXC pour s’y connecter incus exec <non_conteneur> -- <commande>. Dans notre cas nous voulons lancer bash pour ouvrir un shell dans le conteneur : incus exec centos1 -- bash.
Nous pouvons installer des logiciels dans le conteneur comme dans une VM. Pour sortir du conteneur on peut simplement utiliser exit.
Un peu comme avec Docker, LXC utilise des images modèles pour créer des conteneurs. Affichez la liste des images avec incus image list. Trois images sont disponibles l’image centos vide téléchargée et utilisée pour créer centos1 et deux autres images préconfigurée ubuntu_ansible et centos_ansible. Ces images contiennent déjà la configuration nécessaire pour être utilisée avec ansible (SSH + Python + Un utilisateur + une clé SSH).
Supprimez la machine centos1 avec incus stop centos1 && incus delete centos1 –>
Nous avons besoin d’images Linux configurées avec SSH, Python et un utilisateur de connexion (disposant idéalement d’une clé ssh configurée pour éviter d’avoir à utiliser un mot de passe de connection)
Créons à partir des images du remotes un conteneur ubuntu et un autre centos:
incus launch ubuntu_ansible ubu1
incus launch centos_ansible centos1
id_ed25519 qui devrait être présente dans votre dossier ~/.ssh/. Vérifiez cela en lançant ls -l /home/stagiaire/.ssh.ubu1 et centos1 en ssh pour vérifier que la clé ssh est bien configurée et vérifiez dans chaque machine que le sudo est configuré sans mot de passe avec sudo -i.Lorsqu’on développe avec Ansible il est conseillé de le gérer comme un véritable projet de code :
inventory.cfg ou hosts et une configuration locale au projet ansible.cfgNous allons créer un tel projet de code pour la suite du tp1
tp1 sur le Bureau.Open Folder...Un projet Ansible implique généralement une configuration Ansible spécifique décrite dans un fichier ansible.cfg
ansible.cfg avec à l’intérieur:[defaults]
inventory = ./inventory.cfg
roles_path = ./roles
host_key_checking = false # nécessaire pour les labs ou on créé et supprime des machines constamment avec des signatures SSH changées.
stdout_callback = yaml
bin_ansible_callbacks = True
ansible.cfg et ajoutez à l’intérieur notre nouvelle machine hote1.
Il faut pour cela lister les conteneurs lxc lancés.incus list # récupérer l'ip de la machine
Générez une clé si elle n’existe pas avec ssh-keygen.
On va copier cette clé à distance avec ssh-copy-id.
Créez et complétez le fichier inventory.cfg d’après ce modèle:
ubu1 ansible_host=<ip>
[all:vars]
ansible_user=stagiaire
Ansible cherche la configuration locale dans le dossier courant. Conséquence: on lance généralement toutes les commandes ansible depuis la racine de notre projet.
Dans le dossier du projet, essayez de relancer la commande ad-hoc ping sur cette machine.
Ansible implique le cas échéant (login avec clé ssh) de déverrouiller la clé ssh pour se connecter à chaque hôte. Lorsqu’on en a plusieurs il est donc nécessaire de la déverrouiller en amont avec l’agent ssh pour ne pas perturber l’exécution des commandes ansible. Pour cela : ssh-add.
Créez un groupe adhoc_lab et ajoutez les deux machines ubu1 et centos1.
ping sur les deux machines.ansible.cfg. Cependant on peut aussi utiliser une connexion par mot de passe et préciser l’utilisateur et le mot de passe dans l’inventaire ou en lançant la commande.En précisant les paramètres de connexion dans le playbook il et aussi possible d’avoir des modes de connexion différents pour chaque machine.
adhoc_lab, centos_hosts et ubuntu_hosts avec deux machines dans chacun. (utilisez pour cela [adhoc_lab:children])[all:vars]
ansible_user=stagiaire
[ubuntu_hosts]
ubu1 ansible_host=<ip>
[centos_hosts]
centos1 ansible_host=<ip>
[adhoc_lab:children]
ubuntu_hosts
centos_hosts
Dans un inventaire ansible on commence toujours par créer les plus petits sous groupes puis on les rassemble en plus grands groupes.
Nous allons maintenant installer nginx sur nos machines. Il y a plusieurs façons d’installer des logiciels grâce à Ansible: en utilisant le gestionnaire de paquets de la distribution ou un gestionnaire spécifique comme pip ou npm. Chaque méthode dispose d’un module ansible spécifique.
Si nous voulions installer nginx avec la même commande sur des machines centos et ubuntu à la fois, impossible d’utiliser apt car centos utilise dnf. Pour éviter ce problème on peut utiliser le module package qui permet d’uniformiser l’installation (pour les cas simples).
N’hésitez pas consulter extensivement la documentation des modules avec leur exemple ou d’utiliser la commande de documentation ansible-doc <module>
become pour devenir root avant d’exécuter la commande (cf élévation de privilège dans le cours2)Commençons par installer les dépendances de cette application. Tous nos serveurs d’application sont sur ubuntu. Nous pouvons donc utiliser le module apt pour installer les dépendances. Il fournit plus d’option que le module package.
Créons un playbook rudimentaire pour installer nginx.
Relancez le playbook après avoir sauvegardé les modifications. Si cela ne marche pas, pourquoi ?
Re-relancez le playbook après avoir sauvegardé les modifications. Si cela ne marche pas, pourquoi ?
Re-relancez le même playbook une seconde fois. Que se passe-t-il ?
epel-release sur la machine centos.nginx. Que remarque-t-on ?systemd et l’option --check pour vérifier si le service nginx est démarré sur chacune des 2 machines. Normalement vous constatez que le service est déjà démarré (par défaut) sur la machine ubuntu et non démarré sur la machine centos.L’option --check sert à vérifier l’état des ressources sur les machines mais sans modifier la configuration`. Relancez la commande précédente pour le vérifier. Normalement le retour de la commande est le même (l’ordre peut varier).
Lancez la commande avec state=stopped : le retour est inversé.
Enlevez le --check pour vous assurer que le service est démarré sur chacune des machines.
Visitez dans un navigateur l’ip d’un des hôtes pour voir la page d’accueil nginx.
Il existe trois façon de lancer des commandes unix avec ansible:
le module command utilise python pour lancez la commande.
le module shell utilise un module python qui appelle un shell pour lancer une commande.
le module raw.
creates pour simuler de l’idempotence.Créez un fichier dans /tmp avec touch et l’un des modules précédents.
Relancez la commande. Le retour est toujours changed car ces modules ne sont pas idempotents.
Relancer l’un des modules shell ou command avec touch et l’option creates pour rendre l’opération idempotente. Ansible détecte alors que le fichier témoin existe et n’exécute pas la commande.
ansible adhoc_lab --become -m "command touch /tmp/file" -a "creates=/tmp/file"
Nous allons faire que la page d’accueil Nginx affiche des données extraites d’Ansible.
Pour cela nous allons partir à la découverte des variables fournies par Ansible.
Dans Ansible, on peut accéder à la variable ansible_facts : ce sont les faits récoltés par Ansible sur l’hôte en cours.
Pour explorer chacune de ces variables vous pouvez utiliser le module debug dans un playbook:
- name: show vars
debug:
msg: "{{ ansible_facts }}"
Vous pouvez aussi exporter les “facts” d’un hôte en JSON pour plus de lisibilité :
ansible all -m setup --tree ./ansible_facts_export
Puis les lire avec cat ./ansible_facts_export/votremachine.json | jq (il faut que jq soit installé, sinon tout ouvrir dans VSCode avec code ./ansible_facts_export).
jq pour extraire et visualiser des informations spécifiques à partir du fichier JSON. Par exemple, pour voir le type de virtualisation détecté :cat /tmp/ansible_facts/<nom_hôte_ou_IP>.json | jq '.ansible_facts.ansible_virtualization_type'
Nous allons faire que la page d’accueil Nginx affiche des données extraites d’Ansible.
tp1.yml avec à l’intérieur:- hosts: ubu1
tasks:
- name: ping
ping:
Lancez ce playbook avec la commande ansible-playbook <nom_playbook>.
Ajoutez une task utilisant le module systemd:, en ajoutant bien un nom (name:) à cette task, pour s’assurer que le service Nginx est bien lancé.
créons un fichier nommé nginx_index.j2 avec le contenu suivant :
Nom de l'hôte Ansible : {{ ansible_hostname }}
Système d'exploitation : {{ ansible_distribution }} {{ ansible_distribution_version }}
Architecture CPU : {{ ansible_facts['architecture'] }}
Ces variables sont des variables issues de l’étape de collecte de facts Ansible (si on ne les collecte pas, la task échouera).
template:, copiez le fichier nginx_index.j2 à l’emplacement de la configuration Nginx par défaut (c’est /var/www/html/index.html pour Ubuntu).--diff et --check, observez les changements qu’Ansible aurait fait au fichier.Les commandes ad-hoc sont des appels directs de modules Ansible qui fonctionnent de façon idempotente mais ne présente pas les avantages du code qui donne tout son intérêt à l’IaC:
La dimension incrémentale du code rend en particulier plus aisé de construire une infrastructure progressivement en la complexifiant au fur et à mesure plutôt que de devoir tout plannifier à l’avance.
Le playbook est une sorte de script ansible, c’est à dire du code.
Le nom provient du football américain : il s’agit d’un ensemble de stratégies qu’une équipe a travaillé pour répondre aux situations du match. Elle insiste sur la versatilité de l’outil.
ansible-playbookansible-playbook mon-playbook.ymlansible-playbook <fichier_playbook> --limit <groupe_machine> --inventory <fichier_inventaire> --become -vv --diff--check et l’option --diffTrès utile, le mode --check sert à vérifier l’état des ressources sur les machines (dry-run) mais sans modifier la configuration.
L’option --diff permet d’afficher les différences entre la configuration actuelle et la configuration après les changements effectués par les différentes tasks.
Une bonne commande est par exemple :
ansible-playbook --check -vv --diff
Cette commande permet de lancer une simulation d’exécution de playbook, et d’afficher les différences entre la configuration actuelle et la configuration désirée (qui aurait été atteinte sans le --check).
Ansible fonctionne grâce à des modules python téléversés sur sur l’hôte à configurer puis exécutés. Ces modules sont conçus pour être cohérents et versatiles et rendre les tâches courantes d’administration plus simples.
Il en existe pour un peu toute les tâches raisonnablement courantes : un slogan Ansible “Batteries included” ! Plus de 1300 modules sont intégrés par défaut.
ping: un module de test Ansible (pas seulement réseau comme la commande ping)
dnf/apt: pour gérer les paquets sur les distributions basées respectivement sur Red Hat ou Debian.
systemd (ou plus générique service): gérer les services/daemons d’un système.user: créer des utilisateurs et gérer leurs options/permission/groupes
file: pour créer, supprimer, modifier, changer les permission de fichiers, dossier et liens.
La documentation des modules Ansible se trouve à l’adresse https://docs.ansible.com/ansible/latest/modules/file_module.html
Chaque module propose de nombreux arguments pour personnaliser son comportement:
exemple: le module file permet de gérer de nombreuses opérations avec un seul module en variant les arguments.
Il est également à noter que la plupart des arguments sont facultatifs.
Exemple et bonne pratique: toujours préciser state: present même si cette valeur est presque toujours le défaut implicite.
Les playbooks ansible sont écrits au format YAML.
A quoi ça ressemble ?
- 1
- Poire
- "Message à caractère informatif"
clé1: valeur1
clé2: valeur2
clé3: 3
marché: # debut du dictionnaire global "marché"
lieu: Crimée Curial
jour: dimanche
horaire:
unité: "heure"
min: 9
max: 14 # entier
fruits: #liste de dictionnaires décrivant chaque fruit
- nom: pomme
couleur: "verte"
pesticide: avec #les chaines sont avec ou sans " ou '
# on peut sauter des lignes dans interrompre la liste ou le dictionnaire en court
- nom: poires
couleur: jaune
pesticide: sans
légumes: #Liste de 3 éléments
- courgettes
- salade
- potiron
#fin du dictionnaire global
Pour mieux visualiser l’imbrication des dictionnaires et des listes en YAML on peut utiliser un convertisseur YAML -> JSON : https://www.json2yaml.com/.
Notre marché devient:
{
"marché": {
"lieu": "Crimée Curial",
"jour": "dimanche",
"horaire": {
"unité": "heure",
"min": 9,
"max": 14
},
"fruits": [
{
"nom": "pomme",
"couleur": "verte",
"pesticide": "avec"
},
{
"nom": "poires",
"couleur": "jaune",
"pesticide": "sans"
}
],
"légumes": [
"courgettes",
"salade",
"potiron"
]
}
}
Observez en particulier la syntaxe assez condensée de la liste “fruits” en YAML qui est une liste de dictionnaires.
---
# (chaque play commence par un tiret)
- hosts: web # une machine ou groupe de machines
become: yes # lancer le playbook avec "sudo"
vars:
logfile_name: "auth.log"
vars_files:
- mesvariables.yml
roles:
- flaskapp
tasks:
- name: créer un fichier de log
file: # syntaxe yaml extensive : conseillée
path: /var/log/{{ logfile_name }} #guillemets facultatifs
mode: 755
- import_tasks: mestaches.yml
handlers:
- systemd:
name: nginx
state: "reloaded"
---
- name: premier play # une liste de play (chaque play commence par un tiret)
hosts: serveur_web # un premier play
become: yes
gather_facts: false # récupérer le dictionnaires d'informations (facts) relatives aux machines
vars:
logfile_name: "auth.log"
vars_files:
- mesvariables.yml
pre_tasks:
- name: dynamic variable
set_fact:
mavariable: "{{ inventory_hostname + '_prod' }}" #guillemets obligatoires
roles:
- flaskapp
tasks:
- name: installer le serveur nginx
apt: name=nginx state=present # syntaxe concise proche des commandes ad hoc mais moins lisible
- name: créer un fichier de log
file: # syntaxe yaml extensive : conseillée
path: /var/log/{{ logfile_name }} #guillemets facultatifs
mode: 755
- import_tasks: mestaches.yml
handlers:
- systemd:
name: nginx
state: "reloaded"
- name: un autre play
hosts: dbservers
tasks:
...
Un playbook commence par un tiret car il s’agit d’une liste de plays.
Un play est un dictionnaire yaml qui décrit un ensemble de tâches ordonnées en plusieurs sections. Un play commence par préciser sur quelles machines il s’applique puis précise quelques paramètres faculatifs d’exécution comme become: yes pour l’élévation de privilège (section hosts).
La section hosts est obligatoire. Toutes les autres sections sont facultatives !
La section tasks est généralement la section principale car elle décrit les tâches de configuration à appliquer.
La section tasks peut être remplacée ou complétée par une section roles et des sections pre_tasks post_tasks
Les handlers sont des tâches conditionnelles qui s’exécutent à la fin (post traitements conditionnels comme le redémarrage d’un service)
L’élévation de privilège est nécessaire lorsqu’on a besoin d’être root pour exécuter une commande ou plus généralement qu’on a besoin d’exécuter une commande avec un utilisateur différent de celui utilisé pour la connexion on peut utiliser:
Au moment de l’exécution l’argument --become en ligne de commande avec ansible, ansible-console ou ansible-playbook.
La section become: yes
hosts) : toutes les tâches seront executée avec cette élévation par défaut.Pour executer une tâche avec un autre utilisateur que root (become simple) ou celui de connexion (sans become) on le précise en ajoutant à become: yes, become_user: username
pre_tasksrolestaskspost_taskshandlersLes roles ne sont pas des tâches à proprement parler mais un ensemble de tâches et ressources regroupées dans un module un peu comme une librairie developpement. Cf. cours 3.
name: qui décrit lors de l’exécution de la tâche en cours : un des principes de l’IaC est l’intelligibilité des opérations.Pour valider la syntaxe il est possible d’installer et utiliser ansible-lint sur les fichiers YAML.
tp2_flask_deployment.ansible.cfg comme précédemment.[defaults]
inventory = ./inventory.cfg
roles_path = ./roles
host_key_checking = false
ubu1 et ubu2.incus launch ubuntu_ansible ubu1
incus launch ubuntu_ansible ubu2
inventory.cfg.$ incus list # pour récupérer l'adresse ip puis
[all:vars]
ansible_user=stagiaire
[appservers]
ubu1 ansible_host=10.x.y.z
ubu2 ansible_host=10.x.y.z
appservers.ansible all -m ping
Le but de ce projet est de déployer une application flask, c’est a dire une application web python. Le code (très minimal) de cette application se trouve sur github à l’adresse: https://github.com/e-lie/flask_hello_ansible.git.
N’hésitez pas consulter extensivement la documentation des modules avec leur exemple ou d’utiliser la commande de doc ansible-doc <module>
Créons un playbook : ajoutez un fichier flask_deploy.yml avec à l’intérieur:
- hosts: hotes_cible
tasks:
- name: ping
ping:
Lancez ce playbook avec la commande ansible-playbook <nom_playbook>.
Commençons par installer les dépendances de cette application. Tous nos serveurs d’application sont sur ubuntu. Nous pouvons donc utiliser le module apt pour installer les dépendances. Il fournit plus d’options que le module package.
apt installez les applications: python3-dev, python3-pip, python3-virtualenv, virtualenv, nginx, git. Donnez à cette tache le nom: ensure basic dependencies are present. ajoutez pour cela la directive become: yes au début du playbook.En utilisant une loop (et en accédant aux différentes valeurs qu’elle prend avec {{ item }}), on va pouvoir exécuter plusieurs fois cette tâche :
- name: Ensure basic dependencies are present
apt:
name: "{{ item }}"
state: present
loop:
- python3-dev
- python3-pip
- python3-virtualenv
- virtualenv
- nginx
- git
Relancez bien votre playbook à chaque tâche : comme Ansible est idempotent il n’est pas grave en situation de développement d’interrompre l’exécution du playbook et de reprendre l’exécution après un échec.
Ajoutez une tâche systemd pour s’assurer que le service nginx est démarré.
- name: Ensure nginx service started
systemd:
name: nginx
state: started
flask et l’ajouter au groupe www-data. Utilisez bien le paramètre append: yes pour éviter de supprimer des groupes à l’utilisateur. - name: Add the user running webapp
user:
name: "flask"
state: present
append: yes # important pour ne pas supprimer les groupes d'un utilisateur existant
groups:
- "www-data"
N’hésitez pas à tester l’option --diff -v avec vos commandes pour voir l’avant-après.
Pour déployer le code de l’application deux options sont possibles.
sync qui fait une copie rsync.git.Nous allons utiliser la deuxième option (git) qui est plus cohérente pour le déploiement et la gestion des versions logicielles. Allez voir la documentation pour voir comment utiliser ce module.
Utilisez-le pour télécharger le code source de l’application (branche master) dans le dossier /home/flask/hello mais en désactivant la mise à jour (au cas où le code change).
- name: Git clone/update python hello webapp in user home
git:
repo: "https://github.com/e-lie/flask_hello_ansible.git"
dest: /home/flask/hello
version: "master"
clone: yes
update: no
Le langage python a son propre gestionnaire de dépendances pip qui permet d’installer facilement les librairies d’un projet. Il propose également un méchanisme d’isolation des paquets installés appelé virtualenv. Normalement installer les dépendances python nécessite 4 ou 5 commandes shell.
nos dépendances sont indiquées dans le fichier requirements.txt à la racine du dossier d’application. pip a une option spéciale pour gérer ces fichiers.
Nous voulons installer ces dépendances dans un dossier venv également à la racine de l’application.
Nous voulons installer ces dépendances en version python3 avec l’argument virtualenv_python: python3.
même si nous pourrions demander à Ansible de lire ce fichier, créer une variable qui liste ces dépendances et les installer une par une, nous n’allons pas utiliser loop. Le but est de toujours trouver le meilleur module pour une tâche.
Avec ces informations et la documentation du module pip installez les dépendances de l’application.
Notre application sera exécutée en tant qu’utilisateur flask pour des raisons de sécurité. Pour cela le dossier doit appartenir à cet utilisateur or il a été créé en tant que root (à cause du become: yes de notre playbook).
file qui change le propriétaire du dossier de façon récursive. N’hésitez pas à tester l’option --diff -v avec vos commandes pour voir l’avant-après. - name: Change permissions of app directory
file:
path: /home/flask/hello
state: directory
owner: "flask"
group: www-data
recurse: true
Notre application doit tourner comme c’est souvent le cas en tant que service (systemd). Pour cela nous devons créer un fichier service adapté hello.service et le copier dans le dossier /etc/systemd/system/.
Ce fichier est un fichier de configuration qui doit contenir le texte suivant:
[Unit]
Description=Gunicorn instance to serve hello
After=network.target
[Service]
User=flask
Group=www-data
WorkingDirectory=/home/flask/hello
Environment="PATH=/home/flask/hello/venv/bin"
ExecStart=/home/flask/hello/venv/bin/gunicorn --workers 3 --bind unix:hello.sock -m 007 app:app
[Install]
WantedBy=multi-user.target
Pour gérer les fichier de configuration on utilise généralement le module template qui permet à partir d’un fichier modèle situé dans le projet ansible de créer dynamiquement un fichier de configuration adapté sur la machine distante.
Créez un dossier templates, avec à l’intérieur le fichier app.service.j2 contenant le texte précédent.
Utilisez le module template pour le copier au bon endroit avec le nom hello.service.
Utilisez ensuite systemd pour démarrer ce service (avec state: restarted dans le cas où le fichier a changé).
hello.test.conf dans le dossier /etc/nginx/sites-available à partir du fichier modèle:nginx.conf.j2
# {{ ansible_managed }}
# La variable du dessus indique qu'il ne faut pas modifier ce fichier directement, on peut l'écraser dans notre config Ansible pour écrire un message plus explicite à ses collègues
server {
listen 80;
server_name hello.test;
location / {
include proxy_params;
proxy_pass http://unix:/home/flask/hello/hello.sock;
}
}
Utilisez file pour créer un lien symbolique de ce fichier dans /etc/nginx/sites-enabled (avec l’option force: yes pour écraser le cas échéant).
Ajoutez une tache pour supprimer le site /etc/nginx/sites-enabled/default.
Ajouter une tâche de redémarrage de nginx.
Ajoutez hello.test dans votre fichier /etc/hosts pointant sur l’ip d’un des serveur d’application.
Visitez l’application dans un navigateur et debugger le cas échéant.
flask_deploy.yml
Ajoutons des variables pour gérer dynamiquement les paramètres de notre déploiement:
Ajoutez une section vars: avant la section tasks: du playbook.
Mettez dans cette section la variable suivante (dictionnaire):
app:
name: hello
user: flask
domain: hello.test
(il faudra modifier votre fichier /etc/hosts pour faire pointer le domaine hello.test vers l’IP de votre conteneur)
pre_tasks: pour afficher cette variable au début du playbook, c’est le module debug : pre_tasks:
- debug:
msg: "{{ app }}"
Remplacez dans le playbook précédent et les deux fichiers de template:
hello par {{ app.name }}flask par {{ app.user }}hello.test par {{ app.domain }}Relancez le playbook : toutes les tâches devraient renvoyer ok à part les “restart” car les valeurs sont identiques.
cd # Pour revenir dans notre dossier home
git clone https://github.com/Uptime-Formation/ansible-tp-solutions -b tp2_before_handlers_correction tp2_before_handlers
Vous pouvez également consulter la solution directement sur le site de Github : https://github.com/Uptime-Formation/ansible-tp-solutions/tree/tp2_before_handlers_correction
Pour le moment dans notre playbook, les deux tâches de redémarrage de service sont en mode restarted c’est à dire qu’elles redémarrent le service à chaque exécution (résultat: changed) et ne sont donc pas idempotentes. En imaginant qu’on lance ce playbook toutes les 15 minutes dans un cron pour stabiliser la configuration, on aurait un redémarrage de nginx 4 fois par heure sans raison.
On désire plutôt ne relancer/recharger le service que lorsque la configuration conrespondante a été modifiée. c’est l’objet des tâches spéciales nommées handlers.
Ajoutez une section handlers: à la suite
Déplacez la tâche de redémarrage/reload de nginx dans cette section et mettez comme nom reload nginx.
Ajoutez aux deux tâches de modification de la configuration la directive notify: <nom_du_handler>.
Testez votre playbook. il devrait être idempotent sauf le restart de hello.service.
Testez le handler en ajoutant un commentaire dans le fichier de configuration nginx.conf.j2.
- name: template nginx site config
template:
src: templates/nginx.conf.j2
dest: /etc/nginx/sites-available/{{ app.domain }}.conf
notify: reload nginx
...
handlers:
- name: reload nginx
systemd:
name: "nginx"
state: reloaded
# => penser aussi à supprimer la tâche maintenant inutile de restart de nginx précédente
cd # Pour revenir dans notre dossier home
git clone https://github.com/Uptime-Formation/ansible-tp-solutions -b tp2_correction tp2_before_handlers
Vous pouvez également consulter la solution directement sur le site de Github : https://github.com/Uptime-Formation/ansible-tp-solutions/tree/tp2_correction
Nous allons tenter de créer une nouvelle version de votre playbook pour qu’il soit portable entre centos et ubuntu. Pour cela, utilisez la directive when: ansible_os_family == 'Debian' ou RedHat.
Pour le nom du user Nginx, on pourrait ajouter une section de playbook appelée vars: et définir quelque chose comme nginx_user: "{{ 'nginx' if ansible_os_family == "RedHat" else 'www-data' }}
Il faudra peut-être penser à l’installation de Python 3 dans CentOS, et dire à Ansible d’utiliser Python 3 en indiquant dans l’inventaire ansible_python_interpreter=/usr/bin/python3.
Dans un template Jinja2, pour écrire un bloc de texte en fonction d’une variable, la syntaxe est la suivante :
{% if ansible_os_family == "Debian" %}
# ma config spécial Debian
# ...
{% endif %}
Nous allons nous préparer à transformer ce playbook en rôle, plus général.
Plutôt qu’une variable app unique on voudrait fournir au playbook une liste d’application à installer (liste potentiellement définie durant l’exécution).
Identifiez dans le playbook précédent les tâches qui sont exactement communes à l’installation des deux apps.
Créez un nouveau fichier deploy_app_tasks.yml et copier à l’intérieur la liste de toutes les autres tâches mais sans les handlers que vous laisserez à la fin du playbook.
Ce nouveau fichier n’est pas à proprement parler un playbook mais une liste de tâches.
Utilisez include_tasks: (cela se configure comme une task un peu spéciale) pour importer cette liste de tâches à l’endroit où vous les avez supprimées.
Vérifiez que le playbook fonctionne et est toujours idempotent. Note: si vous avez récupéré une solution, il va falloir récupérer le fichier d’inventaire d’un autre projet et adapter la section hosts: du playbook.
Ajoutez une tâche debug: msg={{ app }} (c’est une syntaxe abrégée appelée free-form ) au début du playbook pour visualiser le contenu de la variable.
Note : La version non-free-form (version longue) de cette tâche est :
debug:
msg: {{ app }}
app par une liste flask_apps de deux dictionnaires (avec name, domain, user différents les deux dictionnaires et repository et version identiques).flask_apps:
- name: hello
domain: "hello.test"
user: "flask"
version: master
repository: https://github.com/e-lie/flask_hello_ansible.git
- name: hello2
domain: "hello2.test"
user: "flask2"
version: master
repository: https://github.com/e-lie/flask_hello_ansible.git
Il faudra modifier la tâche de debug par debug: msg={{ flask_apps }}. Observons le contenu de cette variable.
debug:, ajoutez la directive loop: "{{ flask_apps }} (elle se situe à la hauteur du nom de la task et du module) et remplacez le msg={{ flask_apps }} par msg={{ item }}. Que se passe-t-il ? note: il est normal que le playbook échoue désormais à l’étape include_tasksLa directive loop_var permet de renommer la variable sur laquelle on boucle par un nom de variable de notre choix. A quoi sert-elle ? Rappelons-nous : sans elle, on accéderait à chaque item de notre liste flask_apps avec la variable item. Cela nous permet donc de ne pas modifier toutes nos tasks utilisant la variable app et de ne pas avoir à utiliser item à la place.
loop et loop_control+loop_var sur la tâche include_tasks pour inclure les tâches pour chacune des deux applications, en complétant comme suit :- include_tasks: deploy_app_tasks.yml
loop: "{{ A_COMPLETER }}"
loop_control:
loop_var: A_COMPLETER
Créez le dossier group_vars et déplacez le dictionnaire flask_apps dans un fichier group_vars/appservers.yml. Comme son nom l’indique ce dossier permet de définir les variables pour un groupe de serveurs dans un fichier externe.
Testez en relançant le playbook que le déplacement des variables est pris en compte correctement.
Pour la solution : activez la branche tp2_correction avec git checkout tp2_correction.
/etc/hosts via le playbookA l’aide de la documentation de l’option delegate: et du module lineinfile, trouvez comment ajouter une tâche qui modifie automatiquement votre /etc/hosts pour ajouter une entrée liant le nom de domaine de votre app à l’IP du conteneur (il faudra utiliser la variable ansible_host et celle du nom de domaine).
Idéalement, on utiliserait la regex .* {{ app.domain }} pour gérer les variations d’adresse IP
Dans le cas de plusieurs hosts hébergeant nos apps, on pourrait même ajouter une autre entrée DNS pour préciser à quelle instance de notre app nous voulons accéder. Sans cela, nous sommes en train de faire une sorte de loadbalancing via le DNS.
Pour info : la variable {{ inventory_hostname }} permet d’accéder au nom que l’on a donné à une machine dans l’inventaire.
Certaines tâches ne peuvent fonctionner sur une nouvelle machine en check mode.
Pour tester, créons une nouvelle machine et exécutons le playbook avec --check.
Avec ignore_errors: et {{ ansible_check_mode }}, résolvons le problème.
On peut utiliser l’attribut listen dans le handler pour décomposer un handler en plusieurs étapes.
Avec nginx -t, testons la config de Nginx dans le handler avant de reload.
Documentation : https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_handlers.html#naming-handlers
Essayez de déployer une version plus complexe d’application flask avec une base de donnée mysql : https://github.com/miguelgrinberg/microblog/tree/v0.17
Il s’agit de l’application construite au fur et à mesure dans un magnifique tutoriel python. Ce chapitre indique comment déployer l’application sur linux.
Ansible utilise en arrière plan un dictionnaire contenant de nombreuses variables.
Pour s’en rendre compte on peut lancer :
ansible <hote_ou_groupe> -m debug -a "msg={{ hostvars }}"
Ce dictionnaire contient en particulier:
ansible_user par exemple)ansible_facts, c’est à dire des variables dynamiques caractérisant les systèmes cible (par exemple ansible_os_family) et récupéré au lancement d’un playbook.On peut définir et modifier la valeur des variables à différents endroits du code ansible:
vars: du playbook.var_files:group_vars, host_varsdefaults des roles (cf partie sur les roles)set_facts.--extra-vars "version=1.23.45 other_variable=foo"Lorsque définies plusieurs fois, les variables ont des priorités en fonction de l’endroit de définition. L’ordre de priorité est plutôt complexe: https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable
En résumé la règle peut être exprimée comme suit: les variables de runtime sont prioritaires sur les variables dans un playbook qui sont prioritaires sur les variables de l’inventaire qui sont prioritaires sur les variables par défaut d’un role.
https://docs.ansible.com/ansible/latest/reference_appendices/special_variables.html
Les plus utiles:
ansible_facts: faits récoltés par Ansible (Ansible Facts) sur l’hôte en courshostvars: dictionaire de toute les variables rangées par hôte de l’inventaire.ansible_host: information utilisée pour la connexion (ip ou domaine).inventory_hostname: nom de la machine dans l’inventaire.groups: dictionnaire de tous les groupes avec la liste des machines appartenant à chaque groupe.Pour explorer chacune de ces variables vous pouvez utiliser le module debug en mode adhoc ou dans un playbook :
ansible <hote_ou_groupe> -m debug -a "msg={{ ansible_host }}" -vvv
Attention, les facts ne sont pas relevés en mode ad-hoc. Il faut donc utiliser le module debug.
Vous pouvez exporter les ansible_facts en JSON pour plus de lisibilité :
ansible all -m setup --tree ./ansible_facts_export
Puis les lire avec cat ./ansible_facts_export/votremachine.json | jq (il faut que jq soit installé, sinon tout ouvrir dans VSCode avec code ./ansible_facts_export).
Les facts sont des valeurs de variables récupérées au début de l’exécution durant l’étape gather_facts et qui décrivent l’état courant de chaque machine.
ansible_os_family est un fact/variable décrivant le type d’OS installé sur la machine. Elle n’existe qu’une fois les facts récupérés.Lors d’une commande adhoc ansible les facts ne sont pas récupérés : la variable ansible_os_family ne sera pas disponible.
La liste des facts peut être trouvée dans la documentation et dépend des plugins utilisés pour les récupérés: https://docs.ansible.com/ansible/latest/playbook_guide/playbooks_vars_facts.html
when:Elle permet de rendre une tâche conditionnelle (une sorte de if)
- name: start nginx service
systemd:
name: nginx
state: started
when: ansible_os_family == 'RedHat'
Sinon la tâche est sautée (skipped) durant l’exécution.
loop:Cette directive permet d’exécuter une tâche plusieurs fois basée sur une liste de valeurs :
https://docs.ansible.com/ansible/latest/user_guide/playbooks_loops.html
exemple:
- hosts: localhost
tasks:
- name: exemple de boucle
debug:
msg: "{{ item }}"
loop:
- message1
- message2
- message3
On accéde aux différentes valeurs qu’elle prend avec {{ item }}.
On peut également contrôler cette boucle avec quelques paramètres:
- hosts: localhost
vars:
messages:
- message1
- message2
- message3
tasks:
- name: exemple de boucle
debug:
msg: "message numero {{ num }} : {{ message }}"
loop: "{{ messages }}"
loop_control:
loop_var: message
index_var: num
Cette fonctionnalité de boucle était anciennement accessible avec le mot-clé with_items: qui est maintenant déprécié.
La plupart des fichiers Ansible (sauf l’inventaire) sont traités avec le moteur de template python Jinja2.
Ce moteur permet de créer des valeurs dynamiques dans le code des playbooks, des roles, et des fichiers de configuration.
Les variables écrites au format {{ mavariable }} sont remplacées par leur valeur provenant du dictionnaire d’exécution d’Ansible.
Des filtres (fonctions de transformation) permettent de transformer la valeur des variables: exemple : {{ hostname | default('localhost') }} (Voir plus bas)
Pour transformer la valeur des variables à la volée lors de leur appel on peut utiliser des filtres (jinja2) :
{{ hostname | default('localhost') }}La liste complète des filtres ansible se trouve ici : https://docs.ansible.com/ansible/latest/user_guide/playbooks_filters.html
Les fichiers de templates (.j2) utilisés avec le module template, généralement pour créer des fichiers de configuration peuvent contenir des variables et des filtres comme les fichier de code (voir au dessus) mais également d’autres constructions jinja2 comme:
if : {% if nginx_state == 'present' %}...{% endif %}.for : {% for host in groups['appserver'] %}...{% endfor %}.{% include 'autre_fichier_template.j2' %}Il est possible d’importer le contenu d’autres fichiers dans un playbook:
import_tasks: importe une liste de tâches (atomiques)import_playbook: importe une liste de play contenus dans un playbook.Les deux instructions précédentes désignent un import statique qui est résolu avant l’exécution.
En général, on utilise import_* pour améliorer la lisibilité de notre dépôt.
Au contraire, include_tasks permet d’intégrer une liste de tâches dynamiquement pendant l’exécution.
En général, on utilise include_* pour décider quelles tâches, quelles variables ou quels rôles seront inclus au run d’un playbook.
Par exemple :
vars:
apps:
- app1
- app2
- app3
tasks:
- include_tasks: install_app.yml
loop: "{{ apps }}"
Ce code indique à Ansible d’exécuter une série de tâches pour chaque application de la liste. On pourrait remplacer cette liste par une liste dynamique. Comme le nombre d’imports ne peut pas facilement être connu à l’avance on doit utiliser include_tasks.
Documentation additionnelle :
Avec Ansible on dispose d’au moins trois manières de debugger un playbook :
Rendre la sortie verbeuse (mode debug) avec -vvv.
Utiliser une tâche avec le module debug : debug msg="{{ mavariable }}".
Utiliser la directive debugger: always ou on_failed à ajouter à la fin d’une tâche. L’exécution s’arrête alors après l’exécution de cette tâche et propose un interpreteur de debug.
Les commandes et l’usage du debugger sont décrits dans la documentation: https://docs.ansible.com/ansible/latest/user_guide/playbooks_debugger.html
| Command | Shortcut | Action |
|---|---|---|
| p | Print information about the task | |
| task.args[key] = value | Update module arguments | |
| task_vars[key] = value | Update task variables (you must update_task next) | |
| update_task | u | Recreate a task with updated task variables |
| redo | r | Run the task again |
| continue | c | Continue executing, starting with the next task |
| quit | q | Quit the debugger |
Voici, extrait de la documentation Ansible sur les “Best Practice”, l’une des organisations de référence d’un projet ansible de configuration d’une infrastructure:
production # inventory file for production servers
staging # inventory file for staging environment
group_vars/
group1.yml # here we assign variables to particular groups
group2.yml
host_vars/
hostname1.yml # here we assign variables to particular systems
hostname2.yml
library/ # if any custom modules, put them here (optional)
module_utils/ # if any custom module_utils to support modules, put them here (optional)
filter_plugins/ # if any custom filter plugins, put them here (optional)
site.yml # master playbook
webservers.yml # playbook for webserver tier
dbservers.yml # playbook for dbserver tier
roles/
common/ # this hierarchy represents a "role"
... # role code
webtier/ # same kind of structure as "common" was above, done for the webtier role
monitoring/ # ""
fooapp/ # ""
Plusieurs remarques:
--inventory production.group_vars et host_vars. On met à l’intérieur un fichier <nom_du_groupe>.yml qui contient un dictionnaire de variables.playbooks ou operations pour certaines opérations ponctuelles. (cf cours 4)library du projet ou d’un role et on le précise éventuellement dans ansible.cfg.Common : il est utilisé ici pour rassembler les taches de base des communes à toutes les machines. Par exemple s’assurer que les clés ssh de l’équipe sont présentes, que les dépots spécifiques sont présents etc.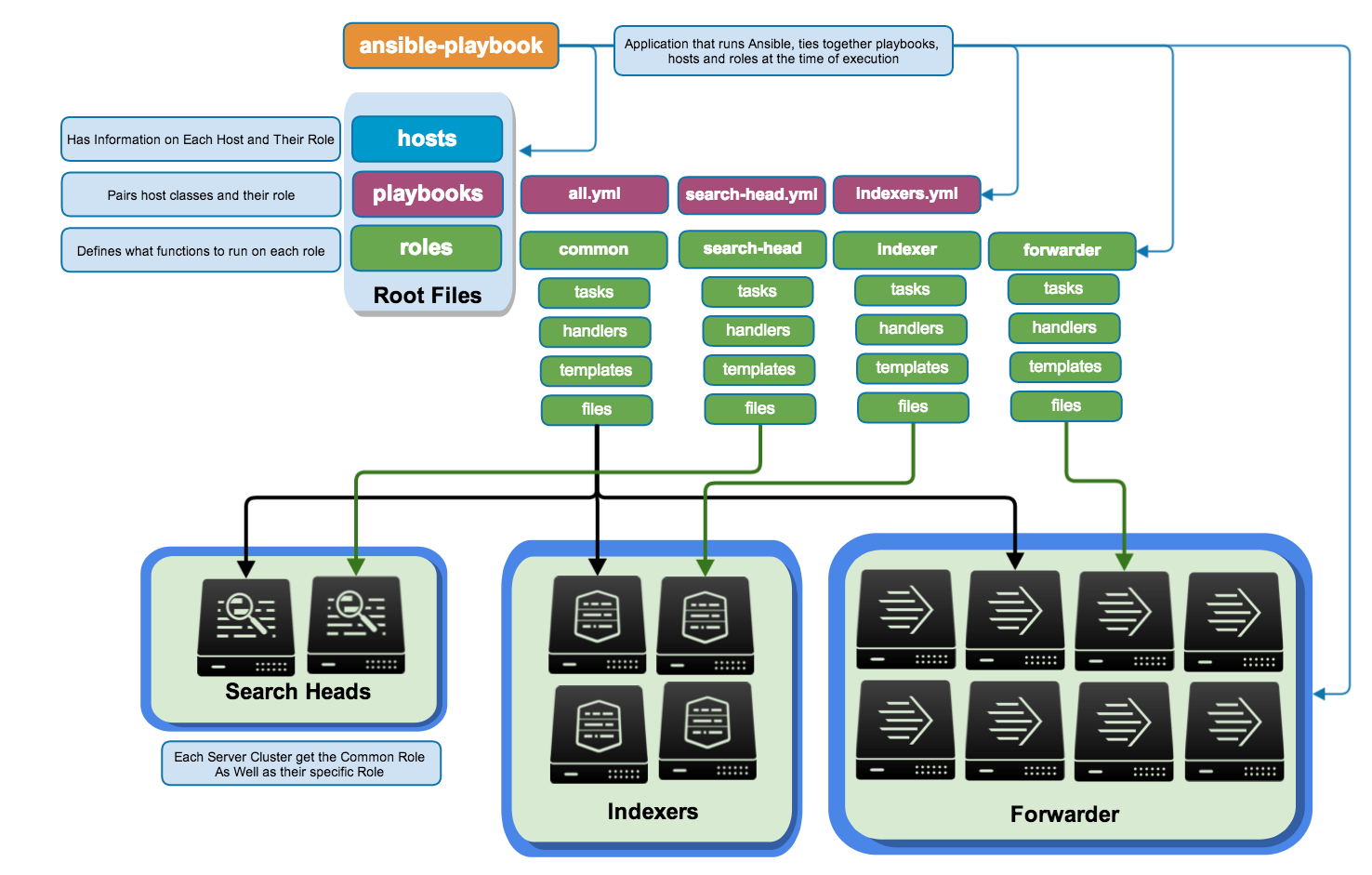
Découper les tâches de configuration en sous ensembles réutilisables (une suite d’étapes de configuration).
Ansible est une sorte de langage de programmation et l’intéret du code est de pouvoir créer des fonction regroupées en librairies et les composer. Les roles sont les “librairies/fonction” ansible en quelque sorte.
Comme une fonction un role prend généralement des paramètres qui permettent de personnaliser son comportement.
Tout le nécessaire doit y être (fichiers de configurations, archives et binaires à déployer, modules personnels dans library etc.)
Remarque ne pas confondre modules et roles : file est un module geerlingguy.docker est un role. On doit écrire des roles pour coder correctement en Ansible, on peut écrire des modules mais c’est largement facultatif car la plupart des actions existent déjà.
Présentation d’un exemple de role : https://github.com/geerlingguy/ansible-role-docker
docker_edition.README en décrire l’usage et un fichier meta/main.yml qui décrit la compatibilité et les dépendanice en plus de la licence et l’auteur.ansible-galaxyUn rôle est un dossier avec des sous dossiers qui répondent à une convention de nommage précise (contrairement à l’organisation d’un projet Ansible, qui peut être plus chaotique), généralement quelque chose comme :
ou encore :
roles/
mediawiki/ # le nom du rôle
tasks/ #
main.yml # <-- fichier de tasks principal
autre.yml # <-- fichier(s) de tasks en plus
handlers/ #
main.yml # <-- handlers file
templates/ # <-- files for use with the template resource
ntp.conf.j2 # <------- templates end in .j2
files/ #
foo.sh # <-- script files for use with the script resource
defaults/ #
main.yml # <-- default lower priority variables for this role
Voici la version exhaustive :
roles/
requirements.yml # la liste des rôles nécessaires et comment les récupérer
mediawiki/ # le nom du rôle
tasks/ #
main.yml # <-- tasks file can include smaller files if warranted
handlers/ #
main.yml # <-- handlers file
templates/ # <-- files for use with the template resource
ntp.conf.j2 # <------- templates end in .j2
files/ #
foo.sh # <-- script files for use with the script resource
vars/ #
main.yml # <-- variables associated with this role
defaults/ #
main.yml # <-- default lower priority variables for this role
meta/ #
main.yml # <-- role dependencies
molecule/ # pour le test du rôle
check.yml
converge.yml
idempotent.yml
verify.yml
# Plus rare :
library/ # roles can also include custom modules
module_utils/ # roles can also include custom module_utils
lookup_plugins/
On constate que les noms des sous dossiers correspondent souvent à des sections du playbook. En fait le principe de base est d’extraire les différentes listes de taches ou de variables dans des sous-dossier
Remarque : les fichier de liste doivent nécessairement s’appeler main.yml" (pas très intuitif)
Remarque2 : main.yml peut en revanche importer d’autre fichiers aux noms personnalisés (exp role docker de geerlingguy)
Le dossier defaults contient les valeurs par défaut des paramètres du role. Ces valeurs ne sont jamais prioritaires (elles sont écrasées par n’importe quelle redéfinition)
Le fichier meta/main.yml est facultatif mais conseillé et contient des informations sur le role
Le dossier files contient les fichiers qui ne sont pas des templates (pour les module copy ou sync, script etc).
C’est le store de roles officiel d’Ansible : https://galaxy.ansible.com/
C’est également le nom d’une commande ansible-galaxy qui permet d’installer des roles et leurs dépendances depuis internet. Un sorte de gestionnaire de paquet pour ansible.
Elle est utilisée généralement sour la forme ansible-galaxy install -r roles/requirements.yml -p roles ou plus simplement ansible-galaxy install <role> mais installe dans /etc/ansible/roles.
Tous les rôles ansible sont communautaires (pas de roles officiels) et généralement stockés sur github.
Mais on peut voir la popularité la qualité et les tests qui garantissement la plus ou moins grande fiabilité du role
Il existe des roles pour installer un peu n’importe quelle application serveur courante aujourd’hui. Passez du temps à explorer le web avant de développer quelque chose avec Ansible
requirements.ymlConventionnellement on utilise un fichier requirements.yml situé dans roles pour décrire la liste des roles nécessaires à un projet.
- src: geerlingguy.repo-epel
- src: geerlingguy.haproxy
- src: geerlingguy.docke
# from GitHub, overriding the name and specifying a specific tag
- src: https://github.com/bennojoy/nginx
version: master
name: nginx_role
ansible-galaxy install -r roles/requirements.yml -p roles.à chaque fois avec un playbook on peut laisser la cascade de dépendances mettre nos serveurs dans un état complexe désiré
Si un role dépend d’autres roles, les dépendances sont décrite dans le fichier meta/main.yml comme suit
---
dependencies:
- role: common
vars:
some_parameter: 3
- role: apache
vars:
apache_port: 80
- role: postgres
vars:
dbname: blarg
other_parameter: 12
Les dépendances sont exécutées automatiquement avant l’execution du role en question. Ce méchanisme permet de créer des automatisation bien organisées avec une forme de composition de roles simple pour créer des roles plus complexe : plutôt que de lancer les rôles à chaque fois avec un playbook on peut laisser la cascade de dépendances mettre nos serveurs dans un état complexe désiré.
Pour des rôles fiables il est conseillé d’utiliser l’outil de testing molecule dès la création d’un nouveau rôle pour effectuer des tests unitaire dessus dans un environnement virtuel comme Docker.
On crée différents types de scénarios, même si celui par défaut par Molecule permet déjà d’avoir un bon test du fonctionnement de notre rôle, en couvrant differents cas dès le début :
check.ymlconverge.ymlidempotent.ymlverify.ymlCréez à la racine du projet le dossier roles dans lequel seront rangés tous les rôles (c’est une convention ansible à respecter).
Les rôles sont sur https://galaxy.ansible.com/, mais difficilement trouvables… cherchons sur GitHub l’adresse du dépôt Git avec le nom du rôle mysql de geerlingguy. Il s’agit de l’auteur d’un livre de référence “Ansible for DevOps” et de nombreux rôles de références.
Pour décrire les rôles nécessaires pour notre projet il faut créer un fichier requirements.yml contenant la liste de ces rôles. Ce fichier peut être n’importe où mais il faut généralement le mettre directement dans le dossier roles (autre convention).
Ajoutez à l’intérieur du fichier:
- src: <adresse_du_depot_git_du_role_mysql>
name: geerlingguy.mysql
Pour installez le rôle lancez ensuite ansible-galaxy install -r roles/requirements.yml -p roles.
Ajoutez la ligne geerlingguy.* au fichier .gitignore pour ne pas ajouter les rles externes à votre dépot git.
Pour installer notre base de données, ajoutez un playbook dbservers.yml appliqué au groupe dbservers avec juste une section:
...
roles:
- <nom_role>
Faire un playbook principal site.yml (le playbook principal par convention) qui importe juste les deux playbooks appservers.yml et dbservers.yml avec import_playbook.
Lancer la configuration de toute l’infra avec ce playbook.
Dans votre playbook dbservers.yml et en lisant le mode d’emploi du rôle (ou bien le fichier defaults/main.yml), écrasez certaines variables par défaut du rôle par des variables personnalisés. Relancez votre playbook avec --diff (et éventuellement --check) pour observer les différences.
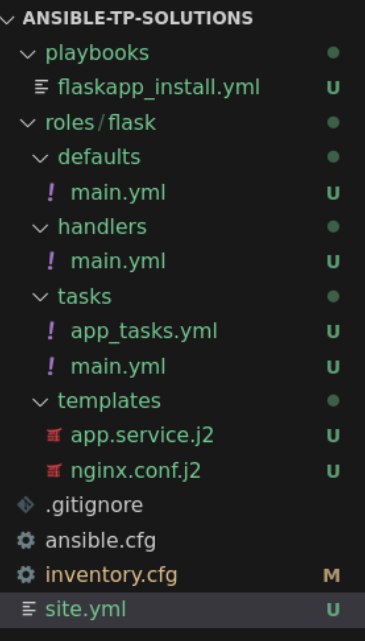
roles dans lequel seront rangés tous les roles (c’est une convention ansible à respecter).flaskapp dans roles.flaskapp
├── defaults
│ └── main.yml
├── handlers
│ └── main.yml
├── tasks
│ ├── deploy_app_tasks.yml
│ └── main.yml
└── templates
├── app.service.j2
└── nginx.conf.j2
Les templates et les listes de handlers/tasks sont a mettre dans les fichiers correspondants (voir plus bas)
Le fichier defaults/main.yml permet de définir des valeurs par défaut pour les variables du role.
Si vous avez fait l’amélioration 2 du TP2 “Rendre le playbook dynamique avec une boucle”
flask_appsflask_apps:
- name: defaultflask
domain: defaultflask.test
repository: https://github.com/e-lie/flask_hello_ansible.git
version: master
user: defaultflask
app :app:
name: defaultflask
domain: defaultflask.test
repository: https://github.com/e-lie/flask_hello_ansible.git
version: master
user: defaultflask
Ces valeurs seront écrasées par celles fournies dans le dossier group_vars (la liste de deux applications du TP2), ou bien celles fournies dans le playbook (si vous n’avez pas déplacé la variable flask_apps). Elle est présente pour éviter que le rôle plante en l’absence de variable (valeurs de fallback).
Occupons-nous maintenant de la liste de tâches de notre rôle. Une règle simple : il n’y a jamais de playbooks dans un rôle : il n’y a que des listes de tâches.
L’idée est la suivante :
on veut avoir un playbook final qui n’aie que des variables (section vars:), un groupe de hosts: et l’invocation de notre rôle
dans le rôle dans le dossier tasks on veut avoir deux fichiers :
main.yml qui sert à invoquer une “boucle principale” (avec include_tasks: et loop:)flask_appsCopiez les tâches (juste la liste de tirets sans l’intitulé de section tasks:) contenues dans le playbook flask_deploy.yml dans le fichier tasks/main.yml.
De la même façon copiez le handler dans handlers/main.yml sans l’intitulé handlers:.
Copiez également le fichier deploy_flask_tasks.yml dans le dossier tasks.
Déplacez vos deux fichiers de template dans le dossier templates du role (et non celui à la racine que vous pouvez supprimer).
Pour appeler notre nouveau role, supprimez les sections tasks: et handlers: du playbook appservers.yml et ajoutez à la place:
roles:
- flaskapp
appservers.yml et debuggez le résultat le cas échéant.--checkflask_apps et lancer le playbook avec --check. Que se passe-t-il ? Pourquoi ?ignore_errors: {{ ansible_check_mode }} au bon endroit. Re-testons.cd # Pour revenir dans notre dossier home
git clone https://github.com/Uptime-Formation/ansible-tp-solutions -b tp3_correction tp3_correction
Vous pouvez également consulter la solution directement sur le site de Github : https://github.com/Uptime-Formation/ansible-tp-solutions/tree/tp3_correction
Essayez différents exemples de projets de Jeff Geerling accessibles sur Github à l’adresse https://github.com/geerlingguy/ansible-for-devops.
Pour des rôles fiables il est conseillé d’utiliser l’outil de testing molecule dès la création d’un nouveau rôle pour effectuer des tests unitaires dessus dans un environnement virtuel comme Docker.
On peut créer des scénarios :
check.yml
converge.yml
idempotent.yml
verify.yml
on peux écrire ces tests avec ansible qui vérifie tout tâche par tâche écrite originalement
ou alors avec testinfra la lib python spécialisée en collecte de facts os
Il y a plein de drivers pas fonctionnels sauf Docker
Pour des cas compliqués, le driver Hetzner Cloud est le meilleur driver VPS
Documentation : https://molecule.readthedocs.io/en/latest/
Créez un compte sur la forge logicielle gitlab.com et créez un projet (dépôt) public.
Affichez et copiez cat ~/.ssh/id_ed25519.pub.
Dans (User) Settings > SSH Keys, collez votre clé publique copiée dans la quesiton précédente.
Suivez les instructions pour pousser le code du projet Ansible sur ce dépôt.
Dans le menu à gauche sur la page de votre projet Gitlab, cliquez sur Build > Pipeline Editor. Cet éditeur permet d’éditer directement dans le navigateur le fichier .gitlab-ci.yml et de commiter vos modification directement dans des branches sur le serveur.
Ajoutez à la racine du projet un fichier .gitlab-ci.yml avec à l’intérieur:
image:
# This linux container (docker) we will be used for our pipeline : ubuntu bionic with ansible preinstalled in it
name: williamyeh/ansible:ubuntu18.04
variables:
ANSIBLE_CONFIG: $CI_PROJECT_DIR/ansible.cfg
deploy:
# The 3 lines after this are used activate the pipeline only when the master branch changes
only:
refs:
- master
script:
- ansible --version
En poussant du nouveau code dans master ou en mergant dans master les jobs sont automatiquement lancés via une nouvelle pipeline : c’est le principe de la CI/CD Gitlab. only: refs: master sert justement à indiquer de limiter l’exécution des pipelines à la branche master.
Cliquez sur commit dans le web IDE et cochez merge to master branch. Une fois validé votre code déclenche donc directement une exécution du pipeline.
Vous pouvez retrouver tout l’historique de l’exécution des pipelines dans la Section CI / CD > Jobs rendez vous dans cette section pour observer le résultat de la dernière exécution.
Notre pipeline nous permet uniquement de vérifier la bonne disponibilité d’ansible.
Elle est basée sur une (vieille) image docker contenant Ansible pour ensuite executer notre projet d’Iinfra as Code.
Créons un runner Gitlab de type shell et installons-le dans notre lab.
Faisons en sorte que c’est ce runner qui se chargera de l’exécution des jobs grâce aux tags.
Remplacez ansible --version par un ping de toutes les machines.
Relancez la pipeline en committant (et en poussant) vos modifications dans master.
Allez observer le job en cours d’exécution.
Enfin lançons notre playbook principal en remplaçant la commande ansible précédente dans la pipeline et committant
ansible-pullhttps://blog.octo.com/ansible-pull-killer-feature/
--url, mettre en place un déploiement “inversé” avec ansible-pull. Il va falloir exécuter un playbook qui s’applique sur localhost ou sur notre hostname (vnc-votreprenom)cron (ou un timer systemd), lancez ce déploiement toutes les 5min, et observez dans les logs.ansible-run.sh, copiez et collez le contenu suivant dans le fichier ansible-run.sh et remplacez la commande par un vrai playbook situé dans le même dossier :#!/bin/bash
ansible-playbook site.yml --diff
chmod +x ansible-run.shPour suivre ce qu’il se passe, ajoutez la ligne suivante dans votre fichier ansible.cfg pour spécifier le chemin du fichier de logs (ansible_log.txt en l’occurrence) :
log_path=./ansible_log.txt
./ansible-run.sh et observez les logs pour tester votre script de déploiement.Sur votre serveur de déploiement (celui avec le projet Ansible), installez le paquet webhook en utilisant la commande suivante :
sudo apt install webhook
Ensuite, créons un fichier de configuration pour le webhook.
nano ou vi par exemple, faites sudo nano /etc/webhook.conf pour créer le fichier puis modifions-le avec le contenu suivant en adaptant la partie /home/formateur/projet-ansible avec le chemin de votre projet, puis enregistrez et quittez le fichier (pour nano, en appuyant sur Ctrl + X, suivi de Y, puis appuyez sur Entrée) :[
{
"id": "redeploy-webhook",
"command-working-directory": "/home/formateur/projet-ansible",
"execute-command": "/home/formateur/projet-ansible/ansible-run.sh",
"include-command-output-in-response": true,
}
]
Lancez le webhook en utilisant la commande suivante dans un nouveau terminal (si le terminal se ferme, le webhook s’arrêtera) :
/usr/bin/webhook -nopanic -hooks /etc/webhook.conf -port 9999 -verbose
Pour tester le webhook, ouvrez simplement un navigateur web et accédez à l’URL suivante, en remplaçant localhost par le nom de votre domaine ou l’adresse IP de votre serveur si nécessaire :
http://localhost:9999/hooks/redeploy-webhook
Le webhook exécutera le script ansible-run.sh, qui lancera votre playbook Ansible.
Le webhook attend que le playbook finisse, laissons la page se charger dans le navigateur, ce qui peut prendre du temps. Ensuite, il affichera le retour de la sortie standard (ou une erreur).
Faites un tail -f ansible_log.txt pour suivre le playbook le temps qu’il se termine, puis observer le retour de la requête HTTP dans votre navigateur.
Dans un fichier .gitlab-ci.yml vous n’avez plus qu’à appeler curl http://votredomaine:9999/hooks/redeploy-webhook pour déclencher l’exécution de votre playbook Ansible en réponse à une requête depuis les serveurs de Gitlab.
deploy:
# The 3 lines after this are used activate the pipeline only when the master branch changes
only:
refs:
- master
script:
- curl http://hadrien.lab.doxx.fr:9999/hooks/redeploy-webhook
Cette configuration est bien plus sécurisée, même si en production nous protégerions le webhook avec un mot de passe (token) pour éviter que le webhook soit déclenché abusivement si quelqu’un en découvrait l’URL.
On pourrait aussi variabiliser le webhook pour faire passer des paramètres à notre script ansible-run.sh.
Build > Pipeline schedules ajoutez un job planifié toutes les heures (fréquence maximum sur gitlab.com) (en production toutes les nuits serait plus adapté) : * * * * * *Les problématiques de sécurité Linux ne sont pas résolues magiquement par Ansible. Tout le travail de réflexion et de sécurisation reste identique mais peut comme le reste être mieux contrôlé grace à l’approche déclarative de l’infrastructure as code.
Si cette problématique des liens entre Ansible et sécurité vous intéresse : Security automation with Ansible
Il est à noter tout de même qu’Ansible est généralement apprécié d’un point de vue sécurité car il n’augmente pas (vraiment) la surface d’attaque de vos infrastructures : il est basé sur SSH qui est éprouvé et ne nécessite généralement pas de réorganisation des infrastructures.
Pour les cas plus spécifiques et si vous voulez éviter SSH, Ansible est relativement agnostique du mode de connexion grâce aux plugins de connexion (voir ci-dessous).
Il faut idéalement éviter de créer un seul compte Ansible de connexion pour toutes les machines :
auth.log + syslog)Il faut utiliser comme nous avons fait dans les TP des logins SSH avec les utilisateurs humain réels des machines et des clés SSH. C’est à dire le même modèle d’authentification que l’administration traditionnelle.
On peut d’ailleurs avec Ansible créer des playbooks pour le roulement régulier des clés publiques et certificats.
Le mode de connexion par défaut de Ansible est SSH, cependant il est possible d’utiliser de nombreux autres modes de connexion spécifiques :
Pour afficher la liste des plugins disponibles lancez ansible-doc -t connection -l.
Une connexion courante est ansible_connection=local qui permet de configurer la machine locale sans avoir besoin d’installer un serveur SSH.
Citons également les connexions ansible_connection=docker et ansible_connection=incus pour configurer des conteneurs Linux, ainsi que ansible_connection=winrm pour les serveurs Windows
Pour débugger les connexions et diagnotiquer leur sécurité on peut afficher les détails de chaque connexion Ansible avec le mode de verbosité maximal (network) en utilisant le paramètre -vvvv.
Le principal risque de sécurité lié à Ansible comme avec Docker et l’IaC en général consiste à laisser traîner des secrets (mots de passe, identité de clients, tokens d’API, secrets de chiffrement, etc.) dans le dépôt de code, ou sur les serveurs (moins problématique).
Attention : les dépôts Git peuvent cacher des secrets dans leur historique. Pour chercher et nettoyer un secret dans un dépôt l’outil le plus courant est BFG : https://rtyley.github.io/bfg-repo-cleaner/ Il existe aussi des produits open source de scan de secrets comme Gitleaks : https://github.com/gitleaks/gitleaks
Pour éviter de divulguer des secrets par inadvertance, il est possible de gérer les secrets avec des variables d’environnement ou avec un fichier variable externe au projet qui échappera au versionning Git, mais ce n’est pas idéal.
Via les plugins de lookup (ansible-doc -t lookup), on peut aussi interroger de nombreux produits et bases de données pour extraire des secrets d’une solution spécifique comme Hashicorp Vault.
Ansible intègre un trousseau de secret appelé Ansible Vault, qui permet de chiffrer des valeurs variables par variables ou des fichiers complets (recommandé). Les valeurs stockées dans le trousseau sont déchiffrées à l’exécution après déverrouillage du trousseau.
ansible-vault create /var/secrets.ymlansible-vault edit /var/secrets.yml ouvre $EDITOR pour changer le fichier de variables.ansible-vault encrypt_file /vars/secrets.yml pour chiffrer un fichier existantansible-vault encrypt_string monmotdepasse permet de chiffrer une valeur avec un mot de passe. le résultat peut être ensuite collé dans un fichier de variables par ailleurs en clair.Pour déchiffrer il est ensuite nécessaire d’ajouter l’option --ask-vault-pass au moment de l’exécution de ansible ou ansible-playbook
Ansible propose une directive no_log: yes qui permet de désactiver l’affichage des valeurs d’entrée et de sortie d’une tâche.
Il est ainsi possible de limiter la prolifération de données sensibles dans les logs qui enregistrent le résultat des playbooks Ansible.
L’automatisation Ansible fait d’autant plus sens dans un environnement d’infrastructure dynamique :
Il existe de nombreuses solutions pour intégrer Ansible avec les principaux providers de cloud (modules Ansible, plugins d’API, intégration avec d’autre outils d’IaC Cloud comme Terraform ou Cloudformation).
Les inventaires que nous avons utilisés jusqu’ici impliquent d’affecter à la main les adresses IP des différents noeuds de notre infrastructure. Cela devient vite ingérable.
La solution Ansible pour ne pas gérer les IP et les groupes à la main est appelée inventaire dynamique ou inventory plugin. Un inventaire dynamique est simplement un programme qui renvoie un JSON respectant le format d’inventaire JSON ansible, généralement en contactant l’API du cloud provider ou une autre source.
$ ./inventory_terraform.py
{
"_meta": {
"hostvars": {
"balancer0": {
"ansible_host": "104.248.194.100"
},
"balancer1": {
"ansible_host": "104.248.204.222"
},
"awx0": {
"ansible_host": "104.248.204.202"
},
"appserver0": {
"ansible_host": "104.248.202.47"
}
}
},
"all": {
"children": [],
"hosts": [
"appserver0",
"awx0",
"balancer0",
"balancer1"
],
"vars": {}
},
"appservers": {
"children": [],
"hosts": [
"balancer0",
"balancer1"
],
"vars": {}
},
"awxnodes": {
"children": [],
"hosts": [
"awx0"
],
"vars": {}
},
"balancers": {
"children": [],
"hosts": [
"appserver0"
],
"vars": {}
}
}%
On peut ensuite appeler ansible-playbook en utilisant ce programme plutôt qu’un fichier statique d’inventaire: ansible-playbook -i inventory_terraform.py configuration.yml
Bonne pratique : Normalement l’information de configuration Ansible doit provenir au maximum de l’inventaire. Ceci est conforme à l’orientation plutôt déclarative d’Ansible et à son exécution descendante (master -> nodes). La méthode à privilégier pour intégrer Ansible à des sources d’information existantes est donc d’utiliser ou développer un plugin d’inventaire.
https://docs.ansible.com/ansible/latest/plugins/inventory.html
La liste : ansible-doc -t inventory -l
On peut cependant alimenter le dictionnaire de variables Ansible au fur et à mesure de l’exécution, en particulier grâce à la directive register et au module set_fact.
Exemple:
- name: 'get postfix default configuration'
command: 'postconf -d'
register: postconf_result
changed_when: false
# the answer of the command give a list of lines such as:
# "key = value" or "key =" when the value is null
- name: 'set postfix default configuration as fact'
set_fact:
postconf_d: >
{{ postconf_d | combine(dict([ item.partition('=')[::2]map'trim') ])) }}
loop: postconf_result.stdout_lines
On peut explorer plus facilement la hiérarchie d’un inventaire statique ou dynamique avec la commande:
ansible-inventory --inventory <inventory> --graph
Voir TP.
kubespraycommunity.kubernetes.k8shttps://docs.ansible.com/ansible/latest/user_guide/playbooks_strategies.html
AWX/Tower
Jenkins
ansible-vault et des credentialsRundeck
Semaphore
Gitlab
Un simple serveur avec Ansible d’installé
Depuis la machine de chaque adminsys, en clonant les bonnes versions des dépôts Git, en récupérant un Vault. Il faudra réfléchir à pousser les logs de façon centralisée
Pour configurer notre infrastructure:
Installez les roles avec ansible-galaxy install -r roles/requirements.yml -p roles.
complétez l’inventaire statique (inventory.cfg)
changer dans ansible.cfg l’inventaire en ./inventory.cfg
Lancez le playbook global site.yml
Utilisez la commande ansible-inventory --graph pour afficher l’arbre des groupes et machines de votre inventaire
Utilisez-la de même pour récupérer l’IP du balancer0 (ou balancer1) avec : ansible-inventory --host=balancer0
Ajoutez hello.test dans /etc/hosts en pointant vers l’ip de balancer0.
Chargez la page hello.test.
Observons ensemble l’organisation du code Ansible de notre projet.
balancers.ymlupgrade_apps.yml permet de mettre à jour l’application en respectant sa haute disponibilité. Il s’agit d’une opération d’orchestration simple en utilisant les 3 (+ 1) serveurs de notre infrastructure.serial qui permet de d’exécuter séquentiellement un play sur une fraction des serveurs d’un groupe (ici 1 à la fois parmi les 3).delegate qui permet d’exécuter une tâche sur une autre machine que le groupe initialement ciblé. Cette directive est au coeur des possibilités d’orchestration Ansible en ce qu’elle permet de contacter un autre serveur (déplacement latéral et non pas master -> node ) pour récupérer son état ou effectuer une modification avant de continuer l’exécution et donc de coordonner des opérations.manually_exclude_backend.yml qui permet de sortir un backend applicatif du pool. Il s’utilise avec des vars prompts (questionnaire) et/ou des variables en ligne de commande.Désactivez le noeud qui vient de vous servir la page en utilisant le playbook manually_exclude_backend.yml en remplissant le prompt. Vous pouvez le réactiver avec -e backend_name=<noeud à réactiver> -e backend_state=enabled.
Rechargez la page : vous constatez que c’est l’autre backend qui a pris le relai.
Nous allons maintenant mettre à jour avec le playbook d’upgrade, lancez d’abord dans un terminal la commande : while true; do curl hello.test; echo; sleep 1; done
Pour louer les machines dans le cloud pour ce TP vous aurez besoin d’un compte DigitalOcean : celui du formateur ici mais vous pouvez facilement utiliser le votre. Il faut récupérer les éléments suivant pour utiliser le compte de cloud du formateur:
Récupérez sur git la paire de clés SSH adaptée :
cd
git clone https://github.com/e-lie/id_ssh_shared.git
chmod 600 id_ssh_shared/id_ssh_shared
ssh-add ~/.ssh/id_ssh_shared pour déverrouiller la clé, le mot de passe est trucmuch42Si vous utilisez votre propre compte, vous aurez besoin d’un token personnel. Pour en créer, allez dans API > Personal access tokens et créez un nouveau token. Copiez bien ce token et collez-le dans un fichier par exemple ~/Bureau/compte_digitalocean.txt (important : détruisez ce token à la fin du TP par sécurité).
cat ~/.ssh/id_ed25519.pubAccount de la sidebar puis Security et ajoutez un nouvelle clé SSH. Notez sa fingerprint dans le fichier précédent.Terraform est un outil pour décrire une infrastructure de machines virtuelles et ressources IaaS (infrastructure as a service) et les créer (commander). Il s’intègre en particulier avec du cloud commercial comme AWS ou DigitalOcean, mais peut également créer des machines dans un cluster en interne (on premise) (VMWare par exemple) pour créer un cloud mixte.
Terraform peut s’installer à l’aide d’un dépôt ubuntu/debian. Pour l’installer lancez :
curl -fsSL https://apt.releases.hashicorp.com/gpg | sudo apt-key add -
sudo apt-add-repository "deb [arch=$(dpkg --print-architecture)] https://apt.releases.hashicorp.com $(lsb_release -cs) main"
sudo apt install terraform
terraform --versionPour pouvoir se connecter à nos VPS, Ansible doit connaître les adresses IP et le mode de connexion SSH de chaque VPS. Il a donc besoin d’un inventaire.
Jusqu’ici nous avons créé un inventaire statique, c’est-à-dire un fichier qui contenait la liste des machines. Nous allons maintenant utiliser un inventaire dynamique : un programme qui permet de récupérer dynamiquement la liste des machines et leurs adresses en contactant une API.
Le fichier qui décrit les VPS et ressources à créer avec Terraform est provisioner/terraform/main.tf. Nous allons commenter ensemble ce fichier.
La documentation pour utiliser Terraform avec DigitalOcean se trouve ici : https://www.terraform.io/docs/providers/do/index.html
Pour que Terraform puisse s’identifier auprès de DigitalOcean nous devons renseigner le token et la fingerprint de clé SSH. Pour cela :
copiez le fichier terraform.tfvars.dist et renommez-le en enlevant le .dist
collez le token récupéré précédemment dans le fichier de variables terraform.tfvars
normalement la clé SSH id_stagiaire est déjà configurée au niveau de DigitalOcean et précisée dans ce fichier. Elle sera donc automatiquement ajoutée aux VPS que nous allons créer.
Maintenant que ce fichier est complété nous pouvons lancer la création de nos VPS :
cd provisioner/terraformterraform init permet à Terraform de télécharger les “drivers” nécessaires pour s’interfacer avec notre provider. Cette commande crée un dossier .terraformterraform plan est facultative et permet de calculer et récapituler les créations et modifications de ressources à partir de la description de main.tfterraform apply permet de déclencher la création des ressources.La création prend environ 1 minute.
Maintenant que nous avons des machines dans le cloud nous devons fournir leurs IP à Ansible pour pouvoir les configurer. Pour cela nous allons utiliser un inventaire dynamique.
Une bonne intégration entre Ansible et Terraform permet de décrire précisément les liens entre resource terraform et hote ansible ainsi que les groupes de machines ansible. Pour cela notre binder propose de dupliquer les ressources dans main.tf pour créer explicitement les hotes ansible à partir des données dynamiques de terraform.
Ouvrons à nouveau le fichier main.tf pour étudier le mapping entre les ressources digitalocean et leur équivalent Ansible.
Pour vérifier le fonctionnement de notre inventaire dynamique, allez à la racine du projet et lancez:
source .env
./inventory_terraform.py
La seconde commande appelle l’inventaire dynamique et vous renvoie un résultat en JSON décrivant les groupes, variables et adresses IP des machines créées avec Terraform.
Complétez le ansible.cfg avec le chemin de l’inventaire dynamique : ./inventory_terraform.py
Utilisez la commande ansible-inventory --graph pour afficher l’arbre des groupes et machines de votre inventaire
Nous pouvons maintenant tester la connexion avec Ansible directement : ansible all -m ping.
sudo snap install semaphore
sudo semaphore user add --admin --name "Your Name" --login your_login --email your-email@examaple.com --password your_password
puis se connecter sur le port 3000
Nécessaire pour Minikube, Semaphore ou Rundeck.
curl https://get.docker.com | sh
curl -sfL https://get.k3s.io | sh
alias kubectl="sudo k3s kubectl"
git clone https://github.com/ansible/awx-operator.git
cd awx-operator
git checkout tags/2.7.2
sudo make deploy
Créer un fichier awx-demo.yml :
---
apiVersion: awx.ansible.com/v1beta1
kind: AWX
metadata:
name: awx-demo
spec:
service_type: nodeport
Puis :
kubectl apply -f awx-demo.yml
kubectl get secret awx-demo-admin-password -o jsonpath="{.data.password}" | base64 --decode ; echo
Identifiez vous sur awx avec le login admin et le mot de passe précédemment configuré.
Dans la section Modèle de projet, importez votre projet. Un job d’import se lance. Si vous avez mis le fichier requirements.yml dans roles les roles devraient être automatiquement installés.
Dans la section credentials, créez un credential de type machine. Dans la section clé privée copiez le contenu du fichier ~/.ssh/id_ssh_tp que nous avons configuré comme clé SSH de nos machines. Ajoutez également la passphrase que vous avez configuré au moment de la création de cette clé.
Créez une ressource inventaire. Créez simplement l’inventaire avec un nom au départ. Une fois créé vous pouvez aller dans la section source et choisir de l’importer depuis le projet, sélectionnez inventory.cfg que nous avons configuré précédemment.
Pour tester tout cela vous pouvez lancez une tâche ad-hoc ping depuis la section inventaire en sélectionnant une machine et en cliquant sur le bouton executer.
Allez dans la section modèle de job et créez un job en sélectionnant le playbook site.yml.
Exécutez ensuite le job en cliquant sur la fusée. Vous vous retrouvez sur la page de job de AWX. La sortie ressemble à celle de la commande mais vous pouvez en plus explorer les taches exécutées en cliquant dessus.
Modifiez votre job, dans la section Planifier configurer l’exécution du playbook site.yml toutes les 5 minutes.
Allez dans la section planification. Puis visitez l’historique des Jobs.
Créons maintenant un workflow qui lance d’abord les playbooks dbservers.yml et appservers.yml puis en cas de réussite le playbook upgrade_apps.yml
Voyons ensemble comment configurer un vault Ansible, d’abord dans notre projet Ansible normal en chiffrant le mot de passe utilisé pour le rôle MySQL. Il est d’usage de préfixer ces variables par secret_.
Voyons comment déverrouiller ce Vault pour l’utiliser dans AWX en ajoutant des Credentials.
Dans un template de tâche ou un workflow AWX, manipulez playbooks/manually_exclude_backend.yml et/ou d’autres playbooks pour réimplementer le scénario du TP5 dans AWX.
Dans notre infra virtuelle, nous avons trois machines dans deux groupes. Quand notre lab d’infra grossit il devient laborieux de créer les machines et affecter les ip à la main. En particulier détruire le lab et le reconstruire est pénible. Nous allons pour cela introduire un playbook de provisionning qui va créer les conteneurs lxd en définissant leur ip à partir de l’inventaire.
[all:vars]
ansible_user=<votre_user>
[appservers]
app1 ansible_host=10.x.y.121 container_image=ubuntu_ansible node_state=started
app2 ansible_host=10.x.y.122 container_image=ubuntu_ansible node_state=started
[dbservers]
db1 ansible_host=10.x.y.131 container_image=ubuntu_ansible node_state=started
Remplacez x et y dans l’adresse IP par celle fournies par votre réseau virtuel lxd (faites incus list et copier simple les deux chiffre du milieu des adresses IP)
Ajoutez un playbook lxd.yml dans un dossier provisioners/lxd contenant:
- hosts: localhost
connection: local
tasks:
- name: Setup linux containers for the infrastructure simulation
lxd_container:
name: "{{ item }}"
state: "{{ hostvars[item]['node_state'] }}"
source:
type: image
alias: "{{ hostvars[item]['container_image'] }}"
profiles: ["default"]
config:
security.nesting: 'true'
security.privileged: 'false'
devices:
# configure network interface
eth0:
type: nic
nictype: bridged
parent: lxdbr0
# get ip address from inventory
ipv4.address: "{{ hostvars[item].ansible_host }}"
# Comment following line if you installed lxd using apt
# url: unix:/var/snap/lxd/common/lxd/unix.socket
wait_for_ipv4_addresses: true
timeout: 600
register: containers
loop: "{{ groups['all'] }}"
# Uncomment following if you want to populate hosts file pour container local hostnames
# AND launch playbook with --ask-become-pass option
- name: Config /etc/hosts file accordingly
become: yes
lineinfile:
path: /etc/hosts
regexp: ".*{{ item }}$"
line: "{{ hostvars[item].ansible_host }} {{ item }}"
state: "present"
loop: "{{ groups['all'] }}"
incus list pour afficher les nouvelles machines de notre infra et vérifier que le serveur de base de données a bien été créé.block et rescueA l’aide de ces pages de la documentation, adaptez les playbooks de https://github.com/Uptime-Formation/exo-ansible-cloud pour gérer le cas où la mise à jour plante (on pourra par exemple tenter une mise à jour en indiquant une branche qui n’existe pas), en décidant de revenir à l’état précédent de l’app et de réactiver l’appserver dans HAProxy.